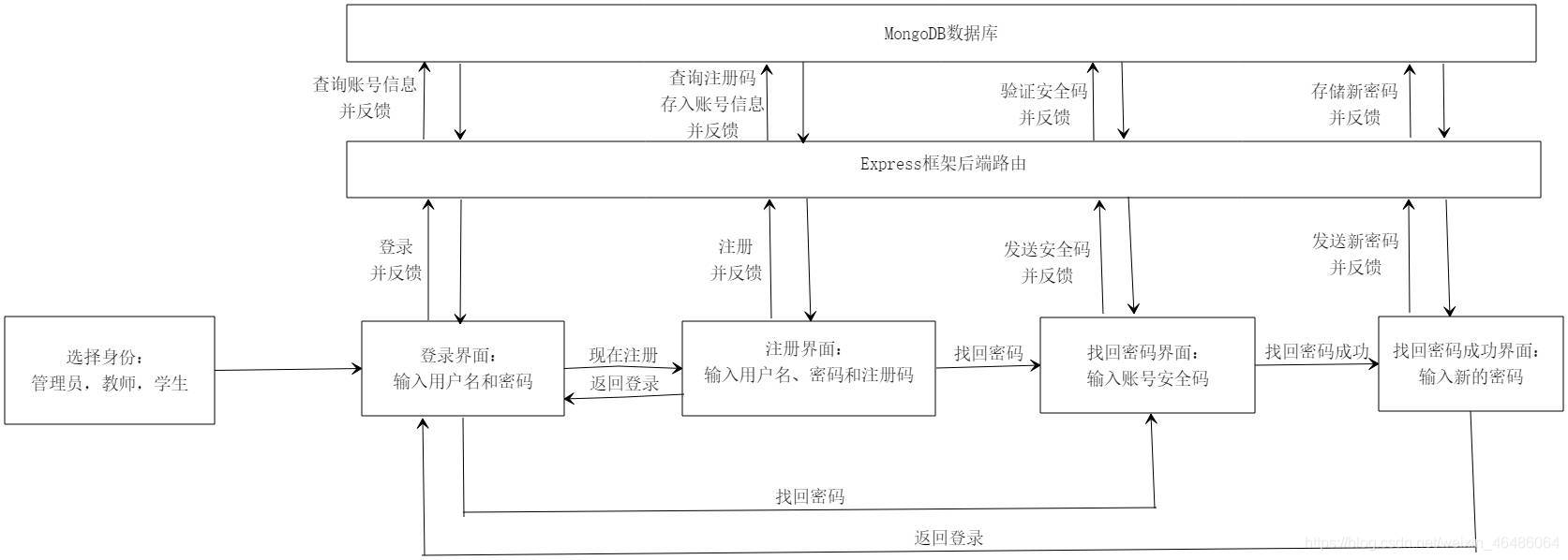
文件上传功能往往是web应用非常重要的功能之一,使用express框架可以简单调用模块实现这一点。
文件上传
客户端上传文件:bootstrap-fileinput插件
插件安装
bootstrap-fileinput插件是基于jQuery和bootstrap的一款集合了文件上传功能优化和界面美化的插件,支持bootstrap3.x和4.x。其包含的css和js文件,需要在bootstrap的css和js文件后引入。https://plugins.krajee.com/file-input https://github.com/kartik-v/bootstrap-fileinput/tree/master/js/locales
插件使用
在html中,可以将上传栏嵌套在bootstrap的折叠中
<button type="button" class="btn btn-secondary" data-toggle="collapse" data-target="#downblock">上传文件</button>
<div id="downblock" class="collapse">
<!--上传框-->
<input type="file" name="txt_file" id="txt_file" multiple class="file-loading" />
</div>
然后需要调用脚本初始化上传功能
$(document).ready(() => { //文档加载完后执行
//新建上传对象
$(function () {
var oFileInput = new FileInput();
oFileInput.Init("txt_file", "/file/upload");//上传时发送Post请求的地址
});
//初始化上传对象
var FileInput = function () {
var oFile = new Object();
oFile.Init = function(ctrlName, uploadUrl) {
var control = $('#' + ctrlName);
//设置上传框的选项
control.fileinput({
language: 'zh', //语言
uploadUrl: uploadUrl, //地址
showUpload: true, //是否显示上传按钮
showCaption: false,//是否显示标题
browseClass: "btn btn-info", //按钮样式
//maxFileSize: 0, //上传最大文件大小(kb),0则无上限
//minFileCount: 0, //同时上传最小文件数
maxFileCount: 5, //同时上传最大文件数
enctype: 'multipart/form-data',
validateInitialCount: true,
previewFileIcon: "<i class='glyphicon glyphicon-king'></i>",
msgFilesTooMany: "选择上传的文件数量({n}) 超过允许的最大数值{m}!",
});
//文件上传完成后触发
$("#txt_file").on("fileuploaded", function (event, data, previewId, index) {
window.location.reload(true);
alert("上传成功!");
});
}
return oFile;
};
});
服务端接受文件:formidable模块
首先在express项目所在文件夹安装好模块
npm install formidable --save
接着在路由中调用formidable模块以及fs模块并接收文件
var express = require('express');
var router = express.Router();
var fs = require("fs");
var formidable = require("formidable");
//上传文件
router.post('/upload', function(req, res) {
var form = new formidable.IncomingForm();
form.encoding = 'utf-8';
form.uploadDir =__dirname.slice(0, -6) + "uploadfiles/tmp"; // 临时文件夹
form.keepExtensions = true; // 文件扩展名
// 读取登录用户所在的班级,便于分文件夹存储
var currentClass = req.session.class || '0';
form.parse(req, function(err, fields, files) {
var filepath = '';
for (var key in files) {
if (files[key].path && filepath == '') {
filepath = files[key].path;
break;
}
}
var targetDir = __dirname.slice(0, -6) + "uploadfiles/" + currentClass + "/";
// 创建存放文件的目录
if (!fs.existsSync(targetDir)) {
fs.mkdir(targetDir, {
recursive: true
}, (err) => {
if (err) throw err;
});
}
var fileExt = filepath.substring(filepath.lastIndexOf("."));
//上传的原文件信息都在field中
var originName = fields.fileId.slice(fields.fileId.indexOf("_") + 1, fields.fileId.lastIndexOf("."));
//重新命名文件
var filename = originName + "-" + getdate() + "-" + new Date().getTime() + fileExt;
var targetFile = targetDir + filename;
fs.rename(filepath, targetFile, err => {
if (err) {
console.info(err);
res.json({
code: -1,
message: "操作失败"
});
} else {
// 上传成功后触发
var fileUrl = __dirname.slice(0, -6) + 'uploadfiles/' + currentClass + "/" + filename;
res.json({
code: 200,
fileUrl: fileUrl
});
console.log("UPLOAD 用户 " + req.session.username + " 上传了文件: " + fileUrl);
}
});
});
})
这样便完成了文件从客户端发送到服务端存储至本地的操作
文件列表推送
客户端主动获取文件列表:fs模块
为了减少一次获取的数据量,仅当用户点击“内容发布”时,向服务端发送get请求,利用AJAX显示文件的列表
var FileFull;
//读取文件列表
function read() {
$.get('/file/list', (data) => {
$("#filelist").children().remove(); // 移除原有列表
FileFull = data; // 存储新的文件列表
data.forEach((item, index, array) => {
// 调节文件名的现显示格式,并且将节点加入表中
showName = item.slice(0, item.lastIndexOf('-')) + item.substring(item.lastIndexOf('.'))
$("#filelist").append('<li href="#" value="' + index + '" class="list-group-item list-group-item-action file" οnclick="showFile(this.innerText, this.value)">' + showName + '</li>');
});
}, "json")
}
//读取文件列表
router.get('/list', function(req, res) {
var currentClass = req.session.class || "0";
fs.readdir(__dirname.slice(0, -6) + "uploadfiles/" + currentClass + "/", (err, files) => {
res.json(files);
res.end();
})
})
服务端只要简单的利用fs模块读取对应文件夹里的文件列表即可
服务端主动推送文件列表:socket.io模块
首先,socket.io基于http,http模块是在bin/www下导入并生成server,因此需要在此文件内引入该模块:
var app = require('../app');
var http = require('http');
var port = normalizePort(process.env.PORT || '3000');
app.set('port', port);
var server = http.createServer(app);
var io = require('socket.io')(server);
app.io(io);
然后便可以在路由中使用socket.io模块
var IO;
router.io = function(io) {
io.on('connection', (socket) => {
socket.on('message', (data) => {
console.log(data);
});
});
IO = io;
return io;
}
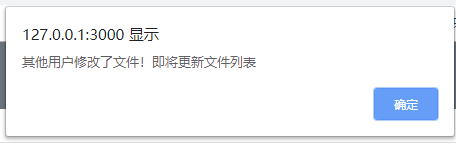
定义io函数,将路由绑定上使用Websocket发送信息的功能。
socket.broadcast.emit('updateFileList', {
code: 200,
data: '请立即更新文件列表'
});
为了避免代码重复,服务端主动发送的内容仅仅是触发客户端,使其再次发送获得最新文件列表的请求。于是,其他用户也能实时看见最新的文件列表。
文件下载、删除等操作
只需要很简单地在客户端发送请求,服务端接收后利用fs模块进行删除,或者利用res.download()发送文件即可。
function downloadFile() {
let filefullname = FileFull[$("#operateFile").val()];
window.open('/file/download?fileName=' + filefullname );
}
需要注意的是,如果直接发送get请求,浏览器将不会对返回的文件进行下载,仅仅保留在response里面。为了下载文件,需要另外打开窗口来替代get请求。