序言
为了在树莓派上架设教学系统,这里以Express为框架,MongoDB作为数据库,利用了部分jQuery语法,实现了局域网内的注册、登录和找回密码服务。
前期设计
流程设计
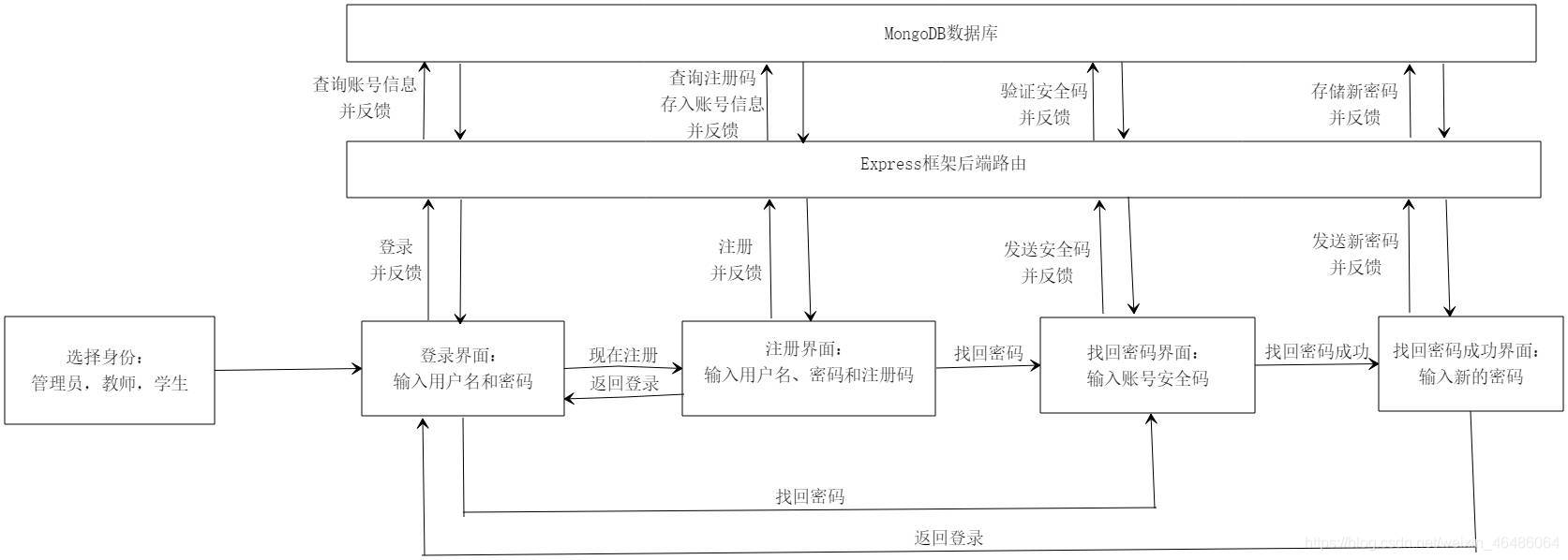
因为是局域网登录,没有使用邮箱验证等联网方式注册账户,而是通过班级的注册码进行验证;同时找回密码的方式是由管理员或教师申请账号安全码。
页面设计

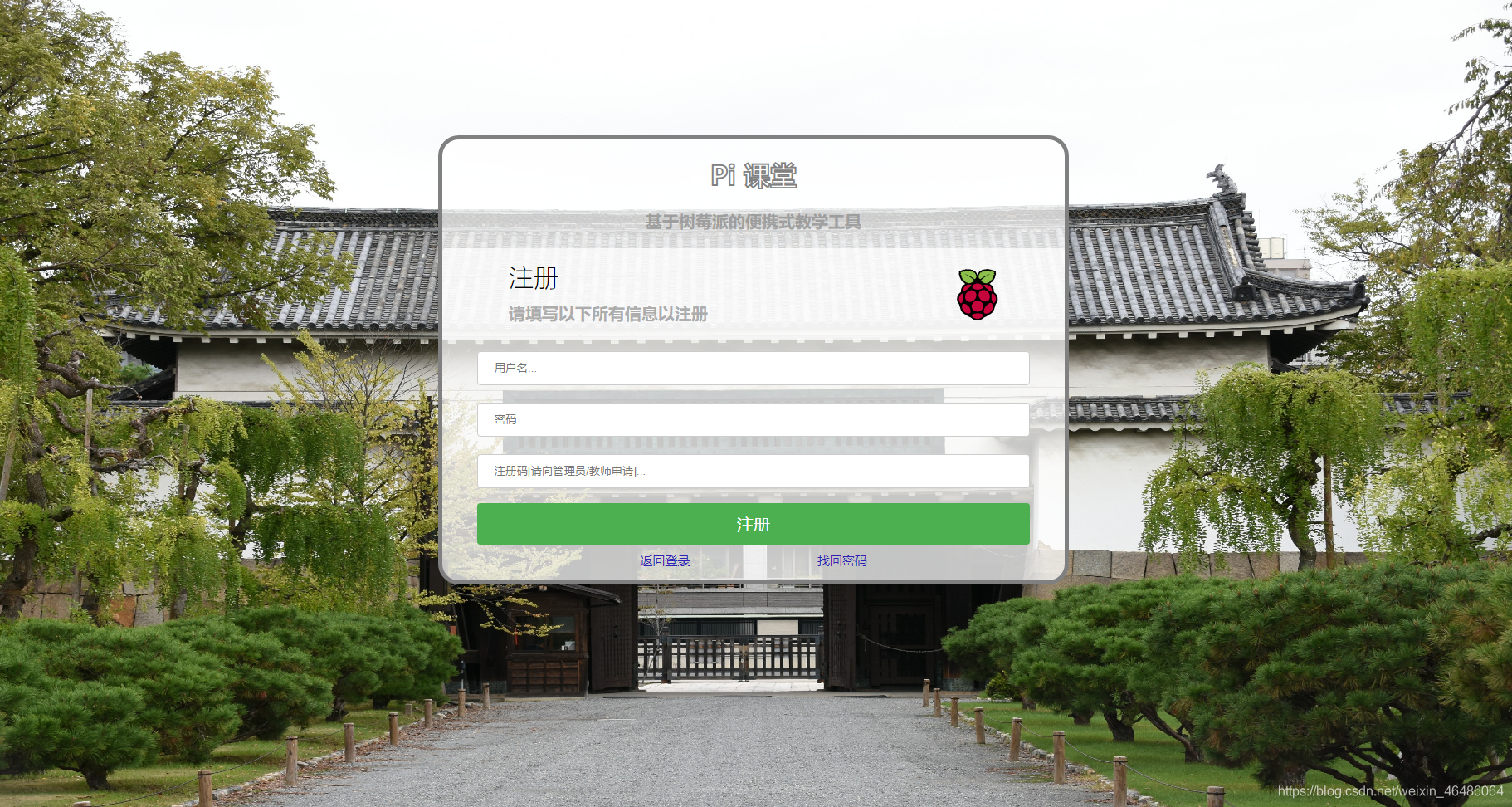
设计上使用的简洁的浮窗式界面,实现上使用了一个html文件,以及两个css文件,分别管理页面的表单样式、其他页面布局样式。二者分离开来,有助于表单样式的复用,将来在其他页面上使用到表单,可以调用同一个css文件。
数据库存储格式
- MongoDB作为非关系型数据库(NoSQL)的一种,相比于关系型数据库,其格式更加灵活,对简单CRUD操作效率更高。
- 同时MongoDB基于文档,以优化的二进制json(bson)格式存储数据,支持了更多数据类型,提高了运行效率,更有分片集群等功能,适合高并发海量数据的存储。
- 在这个例子中,需要进行的操作比较简单,没有事务的需求,因此使用MongoDB作为数据库
学生、教师和管理员的信息分别存在三个集合中,共有的信息基本如下:
| 学(工)号 | 用户名 | 密码 | 权限等级 | 账号安全码 |
| (字符串) | (字符串) | (字符串) | (整型) | (字符串数组) |
注册码存在以下集合中:
| 班级 | 权限 | 注册码 |
| (字符串) | (整型) | (字符串) |
以及存储班级信息的集合
前端脚本
页面切换
脚本第一部分用来在不同的页面之间切换,使用原生的操作方式,利用document.getElementById().style等方法脚本化css,实现对元素的隐藏和展示,达到切换页面的效果
function show_form(value) {
//...
//展示登录框...
}
function to_login() {
document.getElementById('login-form-box').style.display = 'inline';
document.getElementById('register-form-box').style.display = 'none';
document.getElementById('forget-form-box').style.display = 'none';
document.getElementById('find-form-box').style.display = 'none';
//切换到登录界面
}
function to_register() {
//...
//切换到注册界面
}
function to_forget() {
//...
//切换到找回密码界面
}
function to_find() {
//...
//切换到找回密码成功界面
}
jQ请求和响应
脚本第二部分用来向服务器端发送请求,实现注册、登录、找回密码的功能。这部分使用了jQ语法,利用$.post()函数,大大简化了请求操作
$(document).ready(function() {
//注册功能
$("#register-button").click(function() {
//...
//向后端发送POST请求
//发送用户名、密码、注册码和身份(教师、学生)
//接受是否注册成功的消息
});
//登录功能
$("#login-button").click(function() {
//...
//向后端发送POST请求
//发送用户名、密码和身份(教师、学生)
//接受是否登录成功的消息
});
//找回密码功能
$('#forget-button').click(function() {
//...
//向后端发送POST请求
//发送账户安全码和身份(教师、学生)
//接受是否验证成功的消息
//如果验证成功,跳转到重设密码界面
});
//找回成功并设置新密码
$("#find-button").click(function() {
//...
//向后端发送POST请求
//发送账户安全码,新密码和身份(教师、学生)
//接受是否重设密码成功的消息
//如果重设密码成功,跳转到登录界面
});
后端处理
连接MongoDB数据库
首先需要mongodb模块
npm install mongodb --save
然后写一个脚本mongodb.js,整合连接数据库的方法,简化调用
const MongoClient = require("mongodb").MongoClient;//引入模块
const dbname = 'piclass';//数据库名
const url = 'mongodb://localhost:27017/' + dbname;//数据库所在的url
//合并插入单个和多个文档的方法,同时提前写好实际不会发生变化的变量,简化数据库的调用
function insertSome(collection, document, callback) { //只传入集合名,文档和回调函数
if (!Array.isArray(document)) {
//调用连接Mongodb数据库的方法
MongoClient.connect(url, { useNewUrlParser: true, useUnifiedTopology: true }, function(err, db) {
if (err) throw err;
var dbo = db.db(dbname);
dbo.collection(collection).insertOne(document, function(err, res) {
if (err) throw err;
console.log("插入单个文档成功");
db.close();
if (callback) callback(res);
});
});
} else {
//...
//insertMany()方法
}
}
function find(collection, query, callback) {
//...
//简化find方法查找元素
}
function find_select(collection, query, skip, limit, callback) {
//...
//包含限制个数、跳过个数的find方法
}
function updateSome(collection, query, update, justOne, callback) {
//...
//更新一条或者所有符合要求的文档的某个数据
}
function deleteSome(collection, query, justOne, callback) {
//...
//删除符合要求的文档
}
function sort(collection, isAscend, callback) {
//...
//文档排序
}
module.exports.insertSome = insertSome;
module.exports.find = find;
module.exports.find_select = find_select;
module.exports.updateSome = updateSome;
module.exports.deleteSome = deleteSome;
module.exports.sort = sort;
module.exports.clear = function(collection, callback) {
deleteSome(collection, {}, false);
if (callback) callback();
} //清空集合
配置路由
发送至express后台的请求由aqq.js分发到各个路由文件中,这里将登录界面的所有请求都由index.js默认路由来响应。
var express = require('express'); //引入express模块
var db = require('../myscripts/mongodb.js'); //引入操作数据库的自定义模块
var router = express.Router(); //调用路由
/* GET home page. */ //根页面直接使用登录静态页面进行响应
router.get('/', function(req, res, next) {
res.sendfile( __dirname.slice(0, -6) + "public/" + "login.html");
});
/* Login Page */ // /login也同样使用这个静态页面
router.all('/login', function(req, res, next) {
res.sendfile( __dirname.slice(0, -6) + "public/" + "login.html");
});
/* User Rsgister */ //响应注册请求
router.post('/process_register', function(req, res, next) {
//...
//获得用户名、密码、注册码和身份
//1、根据身份进入不同的数据库集合
//2、判断用户名是否已存在
//3、判断注册码是否有效
//4、存储用户数据
//5、传回客户端操作是否成功等信息
})
/* User Login */ //响应登录请求
router.post('/process_login', function(req, res, next) {
//...
//同样地,查询用户名和密码是否存在,并且反馈信息
})
/* Forget Password */ //响应找回密码请求
router.post('/process_forget', function(req, res, next) {
//...
//查询账号安全码是否有效,并且反馈信息
})
/* Find Password */ //响应重设密码请求
router.post('/process_find', function(req, res, next) {
//...
//再次验证安全码,同时将新的密码存入数据库中,并且反馈信息
})
结语
利用这些功能,可以简单搭建一个注册、登录和找回密码功能的web应用。要继续完善,还需要在后面的开发中利用cookie或者session storage等本地存储方案,实现登录状态的保持;增加管理页面,实现高权限账户对低权限账户的管理和注册码、账号安全码的分发;以及对代码进行优化等等。